How Tesla Uses Simulated Data to Improve FSD






Tesla recently launched FSD in China, which has led many people to wonder exactly how they did it so quickly. Tesla isn't allowed to send training data out of China, meaning that it can’t leverage the capacity of the new Cortex Supercomputer Cluster at Giga Texas.
Instead, Tesla is using their generalized model, in combination with Synthetic Training Data, to train FSD for China. Of course, Tesla also uses this same synthetic data to supplement training for North America and for training for Europe. With European FSD on the horizon, we’ll likely see more and more use of synthetic training data for a sure-fire means to handle edge cases.
Simulated Content
Tesla officially refers to the synthetic training data as “Simulated Content” throughout their patent, which is titled “Vision-Based System Training with Synthetic Content.” Let’s break it down into easier-to-understand chunks.
Vision-Only Training
As you may well know, Tesla’s approach to autonomy focuses on using Tesla Vision. That means cameras providing visual data are the primary - and really only - means of acquiring data from outside of the vehicle. They no longer use radar and only use LiDAR to ensure vision sensor accuracy during training.
Capturing all the information from around the car builds a 3D environment that the vehicle uses to plan its path and conduct its decision-making. All that data is processed to build a fairly comprehensive view of what is around the vehicle and what is predicted to be around the vehicle in the future. All of that is also tagged and characterized to help the system prioritize various decisions.
Supervised Learning Model
Tesla’s FSD training is done through a supervised learning model. That means that the training model is fed data that is already labeled, either by humans or by Tesla’s unique AI model. The objects in the images that are being fed are identified and also tagged with position, velocity, and acceleration. This information acts as a ground truth for the AI model to learn from, allowing it to recognize and interpret similar objects and situations when encountered in real-world driving.
Ground Truth Label Data
The ground truth label data is a critical portion of this supervised learning process. The labeled data provides the model with accurate information about objects and their characteristics in the images. This enables Tesla to develop FSD’s robust understanding of the environment around it while it's driving. This data is typically collected from real-world driving scenarios and is either manually or automatically annotated with data.
Generating Simulated Content
Supplementing the real-world ground truth label data, Tesla employs a simulated content system to generate synthetic training data - which is really the key portion of this patent. This system generates synthetic training data that closely resembles the labeled ground truth data from above.
Content Model Attributes and Contextual Labeling
The generation of that simulated content is guided by what Tesla calls “content model attributes,” which are essentially the key characteristics or features that are extracted from the ground truth label data. These could include things like road edges, lane lines, stationary objects, or even dynamic objects like vehicles or pedestrians.
By varying these attributes, the system can create a wide array of simulated scenarios - which means that FSD’s training program is exposed to as many unique and normal situations as possible.
In addition to the attributes, the system also incorporates contextual labeling - which involves adding labels to the simulated content to help refine it with even more detail. These labels can include things like weather conditions, time of day, or even the type of road or environment the vehicle is driving in. All this information is useful context to help develop FSD’s understanding of driving environments.
Training Data Generation
Tesla’s simulated content system generates vast amounts of training data by creating variations of the content models. These variations generally involve making tweaks to the attributes of the objects in the scene - thereby changing environmental conditions, or introducing new types of driving scenarios, like heavy traffic or construction.
Training FSD
Wrapping it all up - the combined dataset of both real-world data and simulated data is then used to train FSD. By continuously providing new sets of both types of input, Tesla can continue to refine and improve FSD further.
Why Use Simulated Content?
It might seem counterintuitive that Tesla utilizes simulated content for training their autonomous driving system when their vehicles already collect vast amounts of real-world driving data. Their vehicles drive hundreds of millions of miles a month, all across the globe - providing them access to an unfathomable amount of unique data. Well, there are a few reasons to do so.
Cost Reduction
One of the primary advantages of using simulated content is cost reduction. By not having to collect, transmit, sort, label, and process the incoming data from the real world, Tesla can instead just create data locally.
That cuts costs for data transmission, data storage, and all the processing and labeling - whether by human or machine. That can be a fairly significant amount when you think about just how much data goes through Tesla’s servers every single day from vehicles all around the world.
Simulating Challenging Conditions
Simulated content allows Tesla to train FSD in a wide range of environmental conditions that might be rare, difficult, or even dangerous to encounter consistently in real-world driving. This can include challenging conditions like heavy rain, fog, or snow - or even nighttime driving in those conditions.
By training the system on this type of content without trying to pull it from real vehicles, Tesla can ensure that FSD remains operable and fairly robust even in more difficult scenarios in the real world.
Edge Cases & Safety
Another crucial benefit of simulated content is the ability to train FSD on edge cases. While we sometimes jokingly refer to edge cases as things like stopping for a school bus, there are real edge cases that may not be frequently encountered in real-world driving scenarios but can pose real safety risks for drivers, occupants, pedestrians, or other road users. Think of things that you could see happening but have never actually seen, like a car falling off a transport trailer or a highway sign falling down.
As such, Tesla simulates many unique edge cases, including sudden pedestrian crossing, unexpected obstacles in the road, or even erratic behavior from other drivers. All these unique simulations are fairly hard to capture regularly in the real world, which means simulating and training on them is essential to ensure safety.
Efficient and Continuous Optimization
Finally, the vast amount of diverse training data that can be generated by Tesla on demand means that they can quickly and efficiently iterate on FSD without needing to wait for real-world data. This means they can keep a continuous learning process going, ensuring that FSD is always improving bit by bit.
If you’re interested in reading more about the guts that make FSD tick, check out our entire series on FSD-related patents from Tesla here.
We’d also recommend our deep dive into Nvidia’s Cosmos - which is a training system for autonomous vehicles that primarily uses synthetic data to train machine models. It's a different take on Tesla’s FSD training cycle that primarily relies on real data, but it does have some similarities to this particular means of using simulated content.



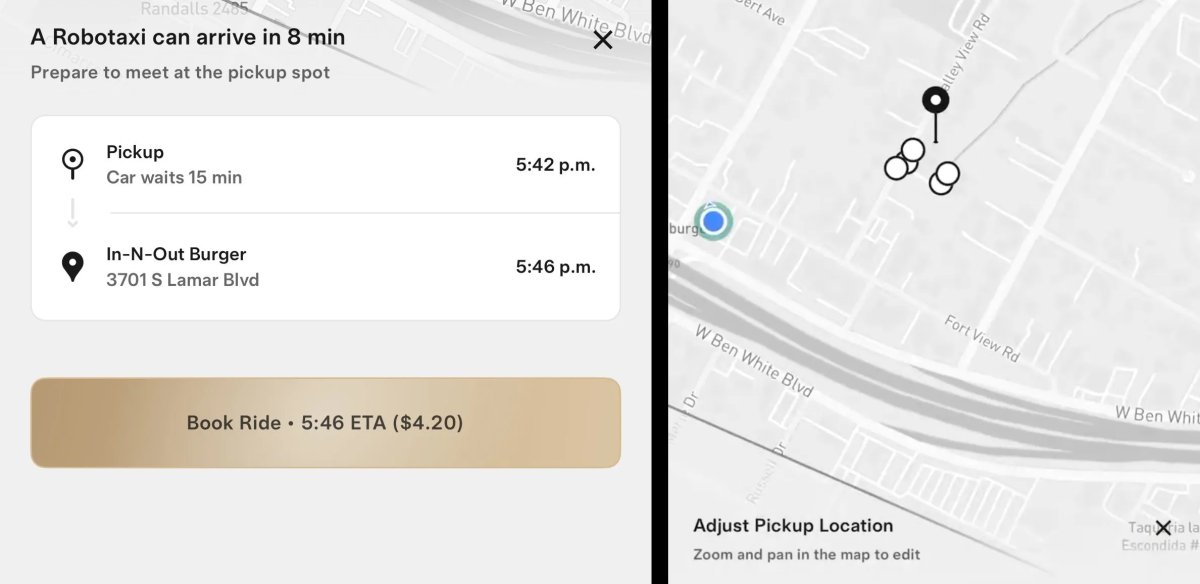

![Tesla Updates Robotaxi App: Adds Adjustable Pick Up Locations, Shows Wait Time and More [VIDEO]](https://www.notateslaapp.com/img/containers/article_images/tesla-app/robotaxi-app/25-7-0/robotaxi-app-25.7.0.webp/4ac9ed40be870cfcf6e851fce21c43b9/robotaxi-app-25.7.0.jpg)











_300w.png)










