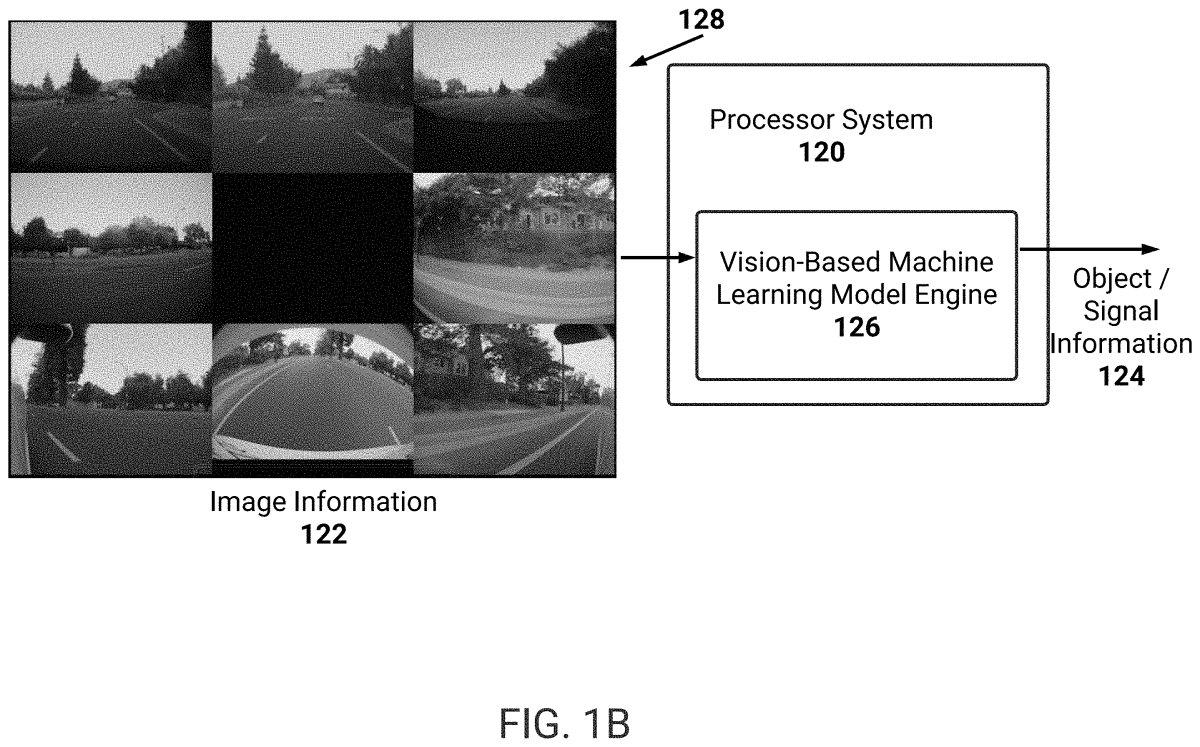
Thanks to a Tesla patent published last year, we have a great look into how FSD operates and the various systems it uses. SETI Park, who examines and writes about patents, also highlighted this one on X.
This patent breaks down the core technology used in Tesla’s FSD and gives us a great understanding of how FSD processes and analyzes data.
To make this easily understandable, we’ll divide it up into sections and break down how each section impacts FSD.
Vision-Based
First, this patent describes a vision-only system—just like Tesla’s goal—to enable vehicles to see, understand, and interact with the world around them. The system describes multiple cameras, some with overlapping coverage, that capture a 360-degree view around the vehicle, mimicking but bettering the human equivalent.
What’s most interesting is that the system quickly and rapidly adapts to the various focal lengths and perspectives of the different cameras around the vehicle. It then combines all this to build a cohesive picture—but we’ll get to that part shortly.
Branching
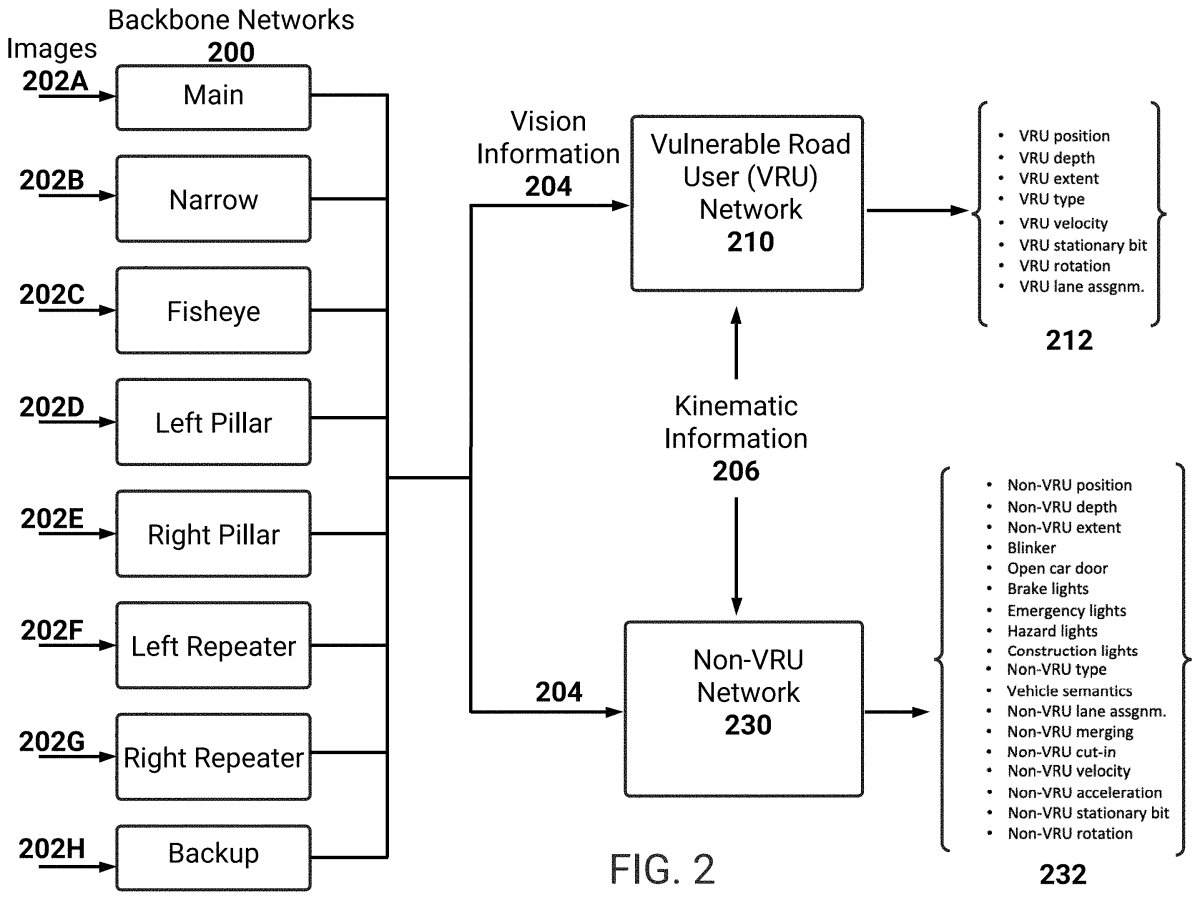
The system is divided into two parts - one for Vulnerable Road Users, or VRUs, and the other for everything else that doesn’t fall into that category. That’s a pretty simple divide - VRUs are defined as pedestrians, cyclists, baby carriages, skateboarders, animals, essentially anything that can get hurt. The non-VRU branch focuses on everything else, so cars, emergency vehicles, traffic cones, debris, etc.
Splitting it into two branches enables FSD to look for, analyze, and then prioritize certain things. Essentially, VRUs are prioritized over other objects throughout the Virtual Camera system.
The many data streams and how they're processed.
Not a Tesla App
Virtual Camera
Tesla processes all of that raw imagery, feeds it into the VRU and non-VRU branches, and picks out only the key and essential information, which is used for object detection and classification.
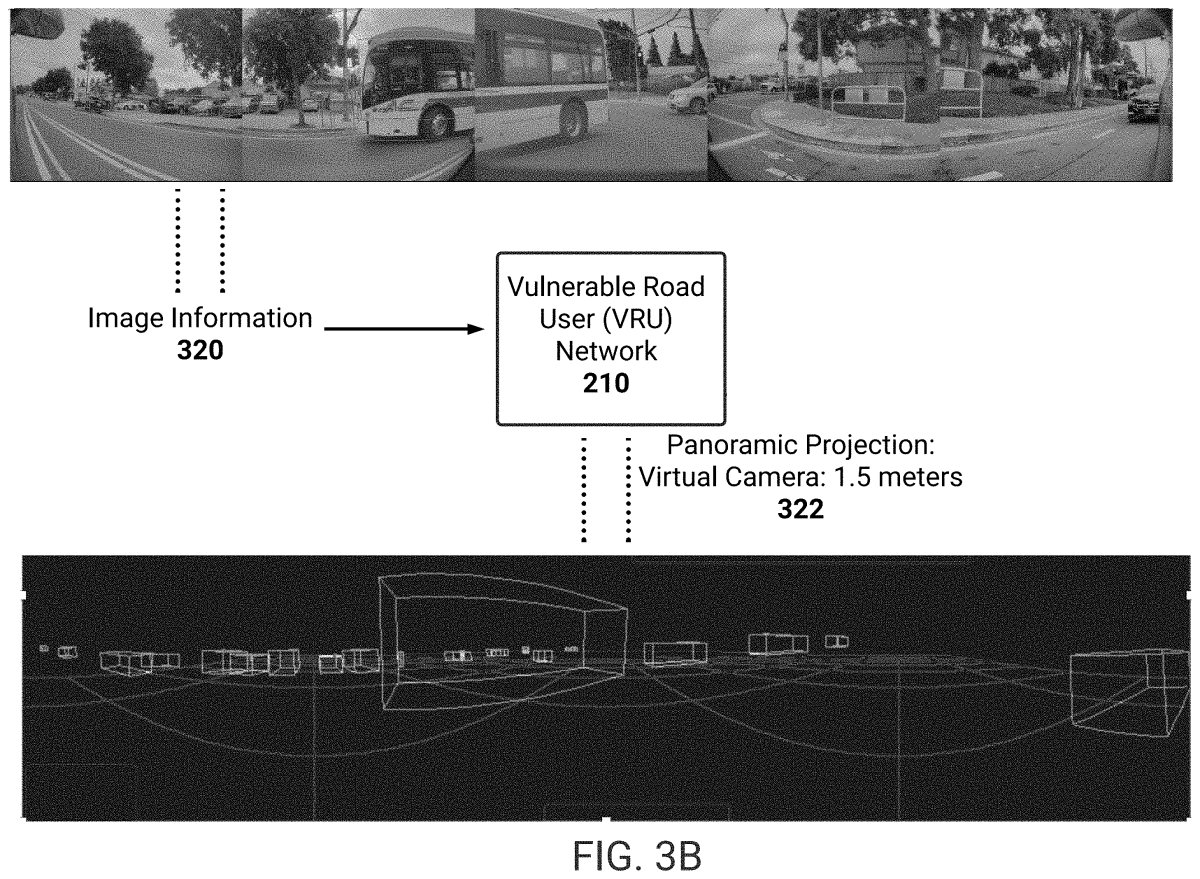
The system then draws these objects on a 3D plane and creates “virtual cameras” at varying heights. Think of a virtual camera as a real camera you’d use to shoot a movie. It allows you to see the scene from a certain perspective.
The VRU branch uses its virtual camera at human height, which enables a better understanding of VRU behavior. This is probably due to the fact that there’s a lot more data at human height than from above or any other angle. Meanwhile, the non-VRU branch raises it above that height, enabling it to see over and around obstacles, thereby allowing for a wider view of traffic.
This effectively provides two forms of input for FSD to analyze—one at the pedestrian level and one from a wider view of the road around it.
3D Mapping
Now, all this data has to be combined. These two virtual cameras are synced - and all their information and understanding are fed back into the system to keep an accurate 3D map of what’s happening around the vehicle.
And it's not just the cameras. The Virtual Camera system and 3D mapping work together with the car’s other sensors to incorporate movement data—speed and acceleration—into the analysis and production of the 3D map.
This system is best understood by the FSD visualization displayed on the screen. It picks up and tracks many moving cars and pedestrians at once, but what we see is only a fraction of all the information it’s tracking. Think of each object as having a list of properties that isn’t displayed on the screen. For example, a pedestrian may have properties that can be accessed by the system that state how far away it is, which direction it’s moving, and how fast it’s going.
Other moving objects, such as vehicles, may have additional properties, such as their width, height, speed, direction, planned path, and more. Even non-VRU objects will contain properties, such as the road, which would have its width, speed limit, and more determined based on AI and map data.
The vehicle itself has its own set of properties, such as speed, width, length, planned path, etc. When you combine everything, you end up with a great understanding of the surrounding environment and how best to navigate it.
The Virtual Mapping of the VRU branch.
Not a Tesla App
Temporal Indexing
Tesla calls this feature Temporal Indexing. In layman’s terms, this is how the vision system analyzes images over time and then keeps track of them. This means that things aren’t a single temporal snapshot but a series of them that allow FSD to understand how objects are moving. This enables object path prediction and also allows FSD to understand where vehicles or objects might be, even if it doesn’t have a direct vision of them.
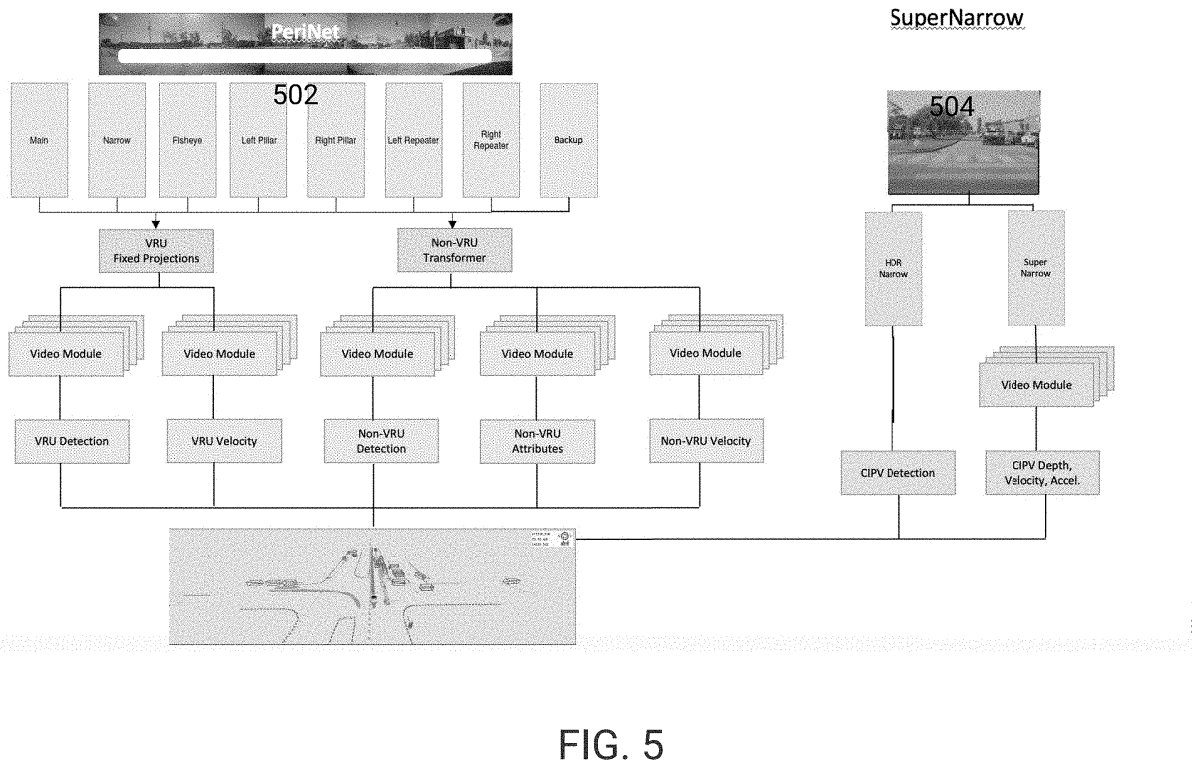
This temporal indexing is done through “Video Modules”, which are the actual “brains” that analyze the sequences of images, tracking them over time and estimating their velocities and future paths.
Once again, heavy traffic and the FSD visualization, which keeps track of many vehicles in lanes around you—even those not in your direct line of sight—are excellent examples.
End-to-End
Finally, the patent also mentions that the entire system, from front to back, can be - and is - trained together. This training approach, which now includes end-to-end AI, optimizes overall system performance by letting each individual component learn how to interact with other components in the system.
How everything comes together.
Not a Tesla App
Summary
Essentially, Tesla sees FSD as a brain, and the cameras are its eyes. It has a memory, and that memory enables it to categorize and analyze what it sees. It can keep track of a wide array of objects and properties to predict their movements and determine a path around them. This is a lot like how humans operate, except FSD can track unlimited objects and determine their properties like speed and size much more accurately. On top of that, it can do it faster than a human and in all directions at once.
FSD and its vision-based camera system essentially create a 3D live map of the road that is constantly and consistently updated and used to make decisions.
Subscribe
Subscribe to our newsletter to stay up to date on the latest Tesla news, upcoming features and software updates.
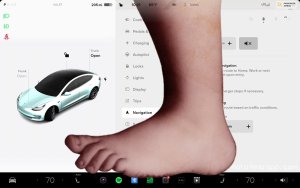
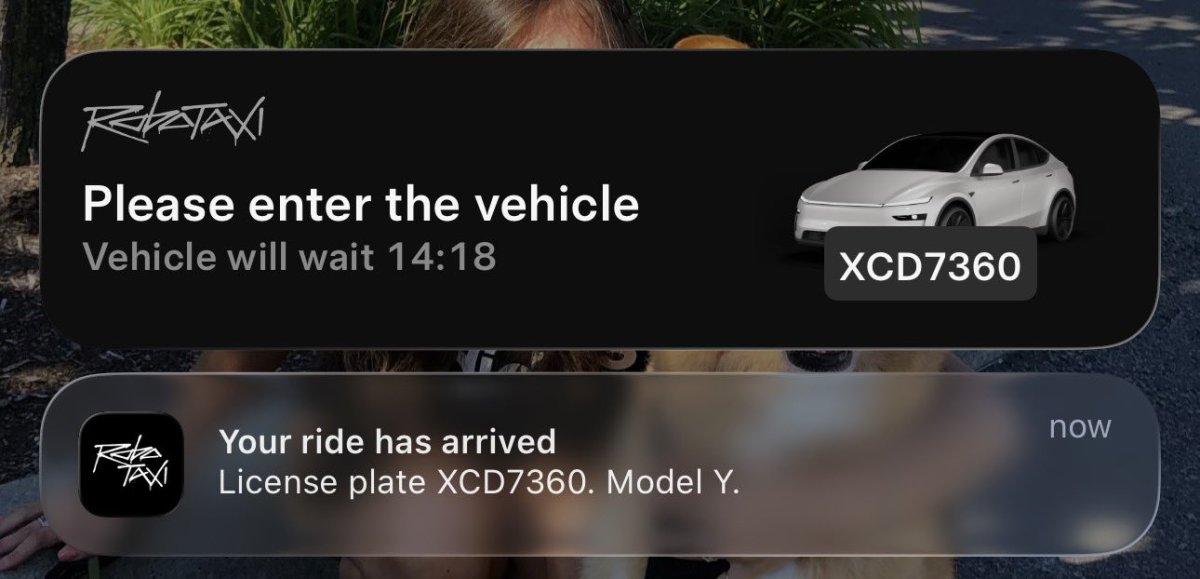
Tesla is rolling out a fairly big update for its iOS and early-access-only Robotaxi app, delivering a suite of improvements that address user feedback from the initial launch last month. The update improves the user experience with increased flexibility, more information, and overall design polish.
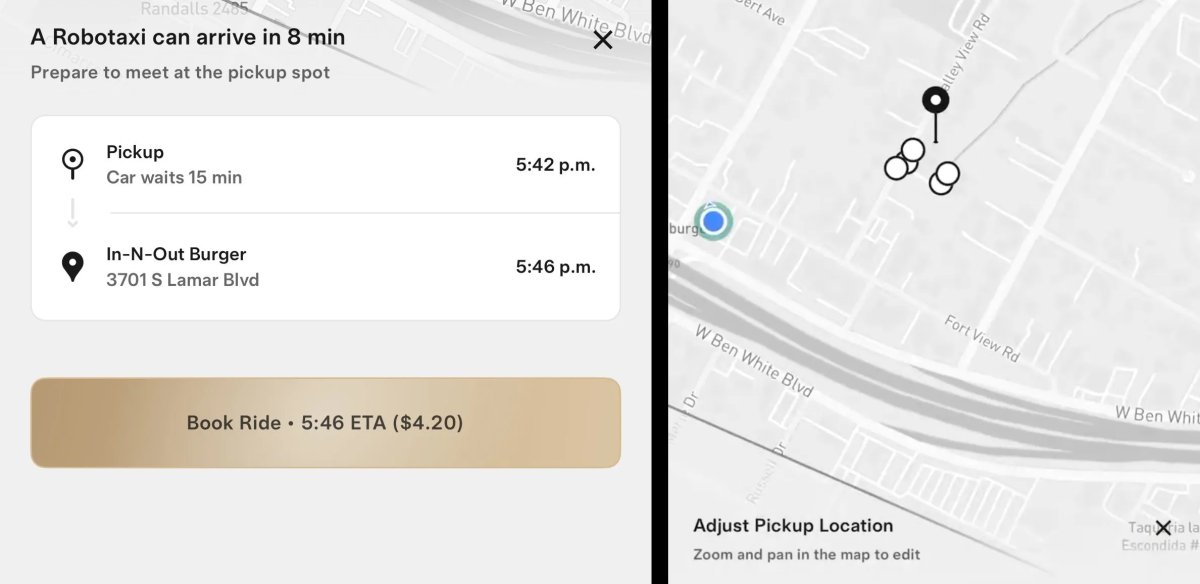
The most prominent feature in this update is that Tesla now allows you to adjust your pickup location. Once a Robotaxi arrives at your pickup location, you have 15 minutes to start the ride. The app will now display the remaining time your Robotaxi will wait for you, counting down from 15:00. The wait time is also shown in the iOS Live Activity if your phone is on the lock screen.
How Adjustable Pickups Work
We previously speculated that Tesla had predetermined pickup locations, as the pickup location wasn’t always where the user was. Now, with the ability to adjust the pickup location, we can clearly see that Tesla has specific locations where users can be picked up.
Rather than allowing users to drop a pin anywhere on the map, the new feature works by having the user drag the map to their desired area. The app then presents a list of nearby, predetermined locations to choose from. Once a user selects a spot from this curated list, they hit “Confirm.” The pickup site can also be changed while the vehicle is en route.
This specific implementation raises an interesting question: Why limit users to predetermined spots? The answer likely lies in how Tesla utilizes fleet data to improve its service.
Here is the new Tesla Robotaxi pickup location adjustment feature.
While the app is still only available on iOS through Apple’s TestFlight program, invited users can download and update the app.
Tesla included these release notes in update 25.7.0 of the Robotaxi app:
You can now adjust pickup location
Display the remaining wait time at pickup in the app and Live Activity
Design improvements
Bug fixes and stability improvements
Nic Cruz Patane
Why Predetermined Pick Up Spots?
The use of predetermined pickup points is less of a limitation and more of a feature. These curated locations are almost certainly spots that Tesla’s fleet data has identified as optimal and safe for an autonomous vehicle to perform a pickup or drop-off.
This suggests that Tesla is methodically “mapping” its service area not just for calibration and validation of FSD builds but also to help perform the first and last 50-foot interactions that are critical to a safe and smooth ride-hailing experience.
An optimal pickup point likely has several key characteristics identified by the fleet, including:
A safe and clear pull-away area away from traffic
Good visibility for cameras, free of obstructions
Easy entry and exit paths for an autonomous vehicle
This change to pick-up locations reveals how Tesla’s Robotaxi Network is more than just Unsupervised FSD. There are a lot of moving parts, many of which Tesla recently implemented, and others that likely still need to be implemented, such as automated charging.
Frequent Updates
This latest update delivers a much-needed feature for adjusting pickup locations, but it also gives us a view into exactly what Tesla is doing with all the data it is collecting with its validation vehicles rolling around Austin, alongside its Robotaxi fleet.
Tesla is quickly iterating on its app and presumably the vehicle’s software to build a reliable and predictable network, using data to perfect every aspect of the experience, from the moment you hail the ride to the moment you step out of the car.
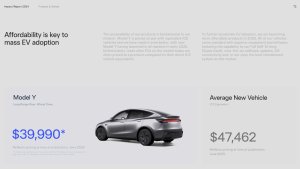
The massive legislative effort titled the "Big Beautiful Bill" is taking direct aim at what has become one of Tesla’s most critical and profitable revenue streams: the sale of US regulatory credits. The bill could eliminate billions of dollars from Tesla’s bottom line each year and will slow down the transition to electric vehicles in the US.
The financial stakes for Tesla are absolutely immense. In 2024, Tesla generated $2.76 billion from selling these credits. This high-margin revenue was the sole reason Tesla posted a profit in Q1 2025; without the $595 million from regulatory credits, Tesla’s reported $409 million in profit would have been a $189 million loss.
How the ZEV Credit System Works
Zero-Emission Vehicle (ZEV) credits are part of state-level programs, led by California, designed to accelerate the adoption of electric vehicles. Each year, automakers are required to hold a certain number of ZEV credits, with the amount based on their total vehicle sales within that state. Under this system, automakers that fail to sell a certain percentage of zero-emission vehicles must either pay a significant fine or purchase credits from a company that exceeds the mandate.
Automakers who fail to sell enough EVs to meet their quota have a deficit and face two choices: pay a hefty fine to the state government for each missing credit (for example, $5,000 per credit in California) or buy credits from a company with a surplus.
As an all-EV company, Tesla generates a massive surplus of these credits. It can then turn around and sell them to legacy automakers at prices cheaper than the fine, creating a win-win scenario: the legacy automaker avoids a larger penalty, and Tesla gains a lucrative, near-pure-profit revenue stream.
This new bill will dismantle this by eliminating the financial penalties for non-compliance, which would effectively make Tesla’s credits worthless. While the ZEV program is a state law, the Big Beautiful Bill will fully eliminate the penalties at a federal level.
A Multi-Billion Dollar Impact
The removal of US ZEGV credits would be a severe blow to Tesla’s financials. One JPMorgan analyst estimated that the move could reduce Tesla’s earnings by over 50%, representing a potential annual loss of $2 billion. While Tesla also earns similar credits in Europe and China, analysts suggest that 80-90% of its credit revenue in Q1 2025 came from US programs.
Why the Program Exists
While the impact on Tesla would be direct and immediate, the credit system has a wider purpose. It creates a strong financial incentive for legacy automakers to develop and accelerate their zero-emission vehicle programs, whether it’s hydrogen, electric, or another alternative.
Eliminating the need for these credits would remove that financial pressure. This could allow traditional automakers to slow their EV transition in the US without the fear of a financial penalty, potentially leading to fewer EV choices for consumers and a slower path to vehicle electrification in the country.
Big, But Not Beautiful
On Sunday Morning TV, Elon Musk was asked his thoughts on the Big Beautiful Bill. They were pretty simple. A bill could be big, or it could be beautiful - I don’t know if it can be both, Musk stated.
Elon Musk in new interview: "I was disappointed to see the massive spending bill, frankly, which increases the budget deficit and undermines the work the DOGE team is doing. I think a bill could be big, or it could be beautiful—I don't know if it can be both." pic.twitter.com/DnyjHN7xCY
The bill poses a threat to Tesla’s bottom line and to the adoption of EVs in the US market, where automakers will no longer have a financial incentive to transition to cleaner vehicles, a market they’ve regularly struggled in when competing against Tesla.
Tesla will have to work carefully in the future to cut expenses to remain profitable after the elimination of these regulatory credits.









![Tesla Updates Robotaxi App: Adds Adjustable Pick Up Locations, Shows Wait Time and More [VIDEO]](https://www.notateslaapp.com/img/containers/article_images/tesla-app/robotaxi-app/25-7-0/robotaxi-app-25.7.0.webp/4ac9ed40be870cfcf6e851fce21c43b9/robotaxi-app-25.7.0.jpg)



_300w.png)